From Feed to Discovery
Why recommendation algorithms are broken and how to fix them
The recommendation algorithm is broken. It is a result of first-order thinking. The algorithm works by recommending the-most-similar-thing™ immediately after you consume some content. It is an infinite ingest of the same. It feeds you and feeds you and feeds you. This is wrong. This isn’t how humans like to consume, and this is causing social problems.
First, how do humans like to consume? Does the recommendation algorithm accurately model what people like? After you eat a baked potato, do you want another baked potato… and then another?
Let’s look at the Beatles’ album Sgt. Pepper’s Lonely Hearts Club Band as an example of how humans consume content globally. What are its credentials for doing so? The Beatles are the best-selling music act in history. Still. Still no one in all history has sold more records than the Beatles. Not Beyonce, not Taylor Swift. More humans spent their money on Beatles records than any other act today, and there are more than double the people on the planet now than when the Beatles broke up in 1970. Sgt. Peppers is their best selling album–32 million records sold.
Planet Earth decided, pre-algorithm, to consume Sgt. Pepper’s as their next album to buy. Why? Was it the most similar thing to the last album that all record player-owning humans consumed? No. The Beatles sold 32 million records because there is literally no musical creation anything like Sgt. Pepper’s. What are the myriad of ways this album differed from anything before it?
It is one of the first concept albums. The album in its entirety has a theme that runs across it and synthesizes the record into a cohesive statement. Until then, albums had merely been a collection of songs.
The album helped turn the album cover into album art. The cover of the album itself became a work of art that could be inspected to incredible detail with the myriad of iconic faces, flowers, costumes, objects. The cover is a radical departure from what before was basically a straightforward advertisement of the contents of the album.
Every song matters. The Beatles didn’t treat the album as a collection of hits and filler. There is no ‘content’. Every song is an individual work of art.
Every song varies from the last. Every song is still completely different from the preceding one and from each other across the entire album. Yet each song perfectly switches the mood. Rocker? Check. Classical Harp? Check. Granny Jazz? Check? Far out psychedelia? Check. Indian Raga? Check. Avant Garde hodge-podge that makes you question the very nature of songwriting and life itself? Check. Who in music today does this? Look at current Spotify numbers. Can you believe that A Day in the Life is actually the 3rd most listened to song on the album? Really??
As the most successful album by the most successful musical act, Sgt. Pepper’s is proof that what people desire from their culture is expansion and growth, dynamism and eclecticism. The Beatles’ audience surely learned to appreciate a new music genre they didn’t know before. “Within You, Without You–what is that instrument? A sitar? What’s a raga? Who is Ravi Shankar?” And now millions of people get turned on to Indian Classical Music who wouldn’t have otherwise.
What the algorithm today provides is the walls closing in. You wonder why trap music is in decline? How is any song by a given artist different from any other? Different is refreshing. Different is discovery. Different is progress. Same is bland. Same is limitation. Same is stagnation. And you hear it in today's music. You see it in your aunt’s social media posts. You see it in today’s politics. Social media is a solitary hall of mirrors and we cannot live off of mirrored glass.
So how do social media, movie streaming, music streaming, news and others go from feed to discovery? How do we program our computers to give people what they want, while expanding their horizons? After all, for all their experimentation and innovation, what The Beatles wrote still boils down to pop tunes. How can we program variation and discovery into the architecture of an algorithm? I think we can go to the 80/20 rule for guidance in creating natural ratios of content delivery.
Discovery:
|--------------------80% things I like and similar ------------—----| |-----20% I don’t know or dislike—--|
Let’s break it down from here.
Within the 80% of things I like and know, you can recommend
|--------------------80% my favorite things ------------—---------| |-----20% Related things —--|
My favorite things being the algorithm as it stands now. I like The Beatles, the algorithm should recommend it to me.
Related things could be The Rolling Stones. I’ve heard of them, but I don’t know their music too well. I should check it out!
Within the 20% of things I don’t know or like, you can recommend
|--------------------80% Things I don’t know —------------—----| |-----20% Things I don’t like —--|
Things I don’t know could be how to sew a cross stitch. How to play polo. What are the most recent fish discovered. Who is the new artist in town.
Things I don’t like. Opposing POVs. Not what is most infurating, but the steel man argument for the other side: Why Rush is better than The Beatles. It’s wrong, but I can understand why someone might think that.
This discovery portal now gives you overall:
64% my favorite things
16% things related to my favorite things, but I haven’t searched for yet
16% things I don’t know.
4% things I don’t like
Algorithms are different in every platform and this discovery formula doesn’t have to be the real rule, but it at least gives people a chance to see something different. Give people what they want, but also confront them with something new and even opposing ideas. I never knew I could enjoy Indian Classical Music until I was confronted with it in Sgt. Pepper’s Lonely Hearts Club Band and it is a beautiful counterpoint to their other creations.
As the world becomes more reliant on software, software will shape our culture. We need to create software systems that model and open humans up to the best of what’s out there. The walls aren’t closing in. There’s a whole world outside your window, waiting for you to discover.
Let's Talk About Reality (And What It Means for AGI)
The world we live in is a rich tapestry of experiences, woven together by a multitude of dimensions. From the colors and shapes we see to the tastes and smells we enjoy, our reality is far more than just physical spaces and the passage of time. But what does all this mean for Artificial General Intelligence (AGI)? Well, the way we navigate this multidimensional reality holds essential lessons for AGI development.
Imagine sitting by a cozy fireplace on a cold winter night. We don't just see the flames. We feel the warmth, hear the crackling sound, and smell the burning wood. For an AGI to understand this experience, it needs sensors that can capture these different dimensions—each sensor would be like a column of data, recording distinct aspects for the AGI to learn from.
But here's where it gets tricky. An AGI could see the light of the fire and smell the smoke, but what about the heat? As it moves closer, the heat increases and the smoke becomes more harmful. The AGI needs self-regulation to know the levels of heat it can tolerate, based on its material composition and limitations. If it gets too close to the fire, will it pull its hand away, just as we would? Or, if it's made of fire-resistant material, will it know it can safely withstand the heat?
And then there's the taste of an apple. Does an AGI need to know the taste of an apple? Would the electricity that sustains it somehow simulate this experience? And, just like humans know the limits of pleasure and the harm of overindulgence, would an AGI understand that staying plugged in all the time, consuming electricity, could harm the greater system?
These questions highlight why AGI needs more than just passive data analysis. It needs to actively interact with the world and learn from these interactions. This is where the wisdom of Aristotle and Heidegger comes in. They recognized that humans aren't just passive observers. We are driven by goals (telos) and desires, actively engaging with the world to fulfill them.
For AGI to truly understand the world as we do, it needs to emulate this sensory-desire-goal-activity-learning feedback loop. It needs a sense of 'being in the world', a purpose that drives its interactions and learning. It needs to be more than a complex calculator—it needs to be an active participant in the world.
Creating an AGI that can navigate our multidimensional reality is an exciting frontier. It's about equipping it with new types of sensors, developing systems that allow it to learn from active engagement, and imbuing it with a sense of purpose and self-regulation. It's about creating an AGI that can understand, engage with, and learn from the world as we do.
So, let's appreciate the richness of our multidimensional reality and strive to create AGI that can truly understand and engage with it. After all, this reality is the stage where we live out our lives and where AGI will need to find its own 'being'.
South Bay, LA: The Unassuming Powerhouse of Global Culture
Beyond the glitz and glamour of Hollywood, and unbeknownst to most Angelenos, The South Bay of Los Angeles has been quietly shaping global culture for decades. Check out the scene in Pulp Fiction where Winston Wolfe offers a ride to Vincent Vega, until he learns he lives in (gasp) Redondo. “Move out of the sticks,” he says. This classic LA chauvinism is pure ignorance of the fact that the South Bay is a cultural dynamo has been punching above its weight for over 60 years.
The Beach Boys, hailing from Hawthorne, revolutionized music with "Pet Sounds." This album, with its innovative harmonies and orchestration, is often compared to The Beatles' "Sgt. Peppers" for its groundbreaking influence. The Beach Boys didn't just define the surf rock genre; they encapsulated the spirit of Southern California, influencing countless musicians and shaping the sound of music to this day. No less than Sir Paul McCartney cites Brian Wilson’s “God Only Knows” as his favorite song.
Hermosa Beach's Black Flag didn't just pioneer hardcore punk; they challenged the norms of the mainstream music industry. By owning their own label, SST Records, one of the most influential of the 1980’s, they paved the way for independent music, setting a precedent for artists to maintain creative control over their work. Their relentless touring and DIY ethos laid the groundwork for the indie rock movement of the 90's and 00's.
And then there’s Quentin Tarantino, one of the most influential directors of our time, started his career in a movie rental store in Manhattan Beach. His films, from "Pulp Fiction" to “Inglorious Basterds,” have left an indelible mark on cinema. Where does Vincent Vega live? Redondo. Where does the climactic bag swap happen at the end of Jackie Brown? Del Amo Mall in Torrance.
San Pedro's Minutemen, another influential band from the South Bay, had a significant impact on the music scene. Their unique fusion of punk, funk, and jazz, along with their politically charged lyrics, influenced bands like the Red Hot Chili Peppers and Sonic Youth. Their album "Double Nickels on the Dime" is considered a landmark of independent rock.
In the literary world, South Bay has been home to some of the most influential writers. Thomas Pynchon, one of the most celebrated postmodern authors, wrote his magnum opus, "Gravity's Rainbow," in Manhattan Beach because his day job was as a rocket scientist for Boeing. Charles Bukowski, the prolific poet and quintessential LA novelist, spent his later years writing in San Pedro. Joan Didion, another literary giant, resided for a time in Palos Verdes.
John Van Hamersveld, started his career in El Segundo and created iconic works that defined the visual culture of the 1960s and 70s. His "Endless Summer" poster, with its vibrant colors and stylized design, is one of the most recognizable images of surf culture. Oh, and he also did the album covers for Magical Mystery Tour by the Beatles and Exile on Mainstreet by The Rolling Stones.
And let’s not forget Hermosa Beach's Jack Black, a titan in both the film and music industries. Black's comedic prowess has propelled him to be one of the biggest box office draws in the world, with standout performances in films like "School of Rock" and "Kung Fu Panda." His unique sense of humor and charisma has made him one of the most recognizable comedic actors of his generation. Beyond his film career, Black is also the frontman of the band Tenacious D. His musical talent, combined with his comedic flair, has resulted in a unique fusion of rock and comedy that has delighted audiences worldwide. Black's dual success in film and music underscores the diverse talent that the South Bay has produced.
South Bay's cultural impact is undeniable. It's a powerhouse that's been shaping music, literature, film, and art on a global scale. It's time we recognize South Bay for what it truly is: an unassuming cultural giant that's been delivering knockout punches, defining global culture on multiple fronts for decades.
The Slipping Horizon: Navigating the Volatile Seas of Post-Reality Markets
In the age of data science and social media, the financial markets have become a tempestuous sea, characterized by a phenomenon I call "The Slipping Horizon." This is a state of constant deferral of market outcomes, a cycle of anticipation and repositioning, driven by predictive analytics and mass repositioning. It's a phenomenon that has turned markets into a theatre of extreme volatility, where fortunes are made and lost with alarming speed, and where traditional measures of value often seem to be cast adrift.
Investing, at its heart, should be about directing capital to where it can produce real-world value, with the expectation that this value will yield returns over time. Yet, in the era of the slipping horizon, this fundamental principle is being distorted. Major companies are being valued at levels that defy traditional analysis, and they are able to maintain these valuations due to the reflexive nature of modern markets.
Consider the case of NVIDIA, a leading player in the semiconductor industry. Its valuation skyrocketed in a relatively short period, driven not just by its strong performance and promising prospects in AI and gaming, but also by a wave of positive sentiment amplified by social media and data-driven predictions. Similarly, Tesla has maintained a persistently high valuation, despite skepticism from many traditional analysts. Its stock price seems to be buoyed by a combination of its visionary leadership, its potential to disrupt the automotive industry, and a surge of retail investors influenced by social media hype.
On the flip side, we have seen dramatic falls from grace, such as the failure of First Republic Bank. Despite its solid fundamentals, the bank found itself caught in a storm of negative sentiment after prominent investors discussed the interest rate risk of its reserves on Twitter following a quick increase in rates by the Federal Reserve. This led to a major bank run, amplified by social media, resulting in a rapid decline in its stock price.
These examples illustrate the volatile seas we are navigating. The confluence of data analytics, social media hype, and the rapid dissemination of information can create waves of sentiment that lift certain stocks to dizzying heights and sink others to crushing depths. This volatility is further amplified by the slipping horizon effect, as investors constantly reposition their portfolios in response to the latest predictions, creating a self-perpetuating cycle of anticipation and repositioning.
In these turbulent waters, the horizon keeps slipping forward. The expected downturns are constantly deferred, creating a sense of perpetual motion without a clear destination. This can lead to a sense of disorientation, as investors struggle to make sense of the shifting landscape.
In conclusion, as we navigate the volatile seas of post-reality markets, we must keep our eyes firmly fixed on the slipping horizon. We must strive to balance the power of predictive analytics with a thoughtful, long-term investment strategy, ensuring that we are not merely reacting to the latest predictions, but also making informed decisions based on careful analysis. We must remember that investing is about directing capital to where it can produce real-world value, and not be swayed by the shifting tides of sentiment. The seas may be rough, but with careful navigation, we can chart a course towards a sustainable financial future.
The Bias-Variance Tradeoff
The Setup
One of the most fundamental skills in Artificial Intelligence and Machine Learning modeling is understanding what causes your model to make erroneous predictions. To make as accurate predictions as we can, we must reduce our model’s error rate and doing so requires a firm understanding of what statisticians call The Bias-Variance Tradeoff.
How well does your model predict when you test it with new data? There are three potential sources of model error:
Total Error = Variance + Bias^2 + Noise
Since bias and variance describe competing problems with your modeling procedure, you need to know which is the source of your model’s high error rate, otherwise you risk exacerbating the issue.
Once you understand what the tradeoff between bias and variance means for the underfitness or overfitness of your model, you can employ the appropriate method to minimize your model’s rate of error and make better predictions.
Definitions
Variance - The squared difference between test values and the expected (model) values. How far off was our expectation from reality? High variance between test data and model output is a sign the model is overfit to the training data.
Variance = (Test Value - Expected Value)^2
Bias - Error of a given model because the model implements, and is biased toward, a particular kind of solution, e.g. a Linear Classifier. This model bias is inherent to the model solution and cannot be overcome by training with more or different data. High bias is a sign the model is underfit to the training data.
Noise - Irreducible error inherent to the dataset. It goes without saying, the world is imperfect. In any case, nothing can be done about this. Moving on…
But what are bias and variance, really?
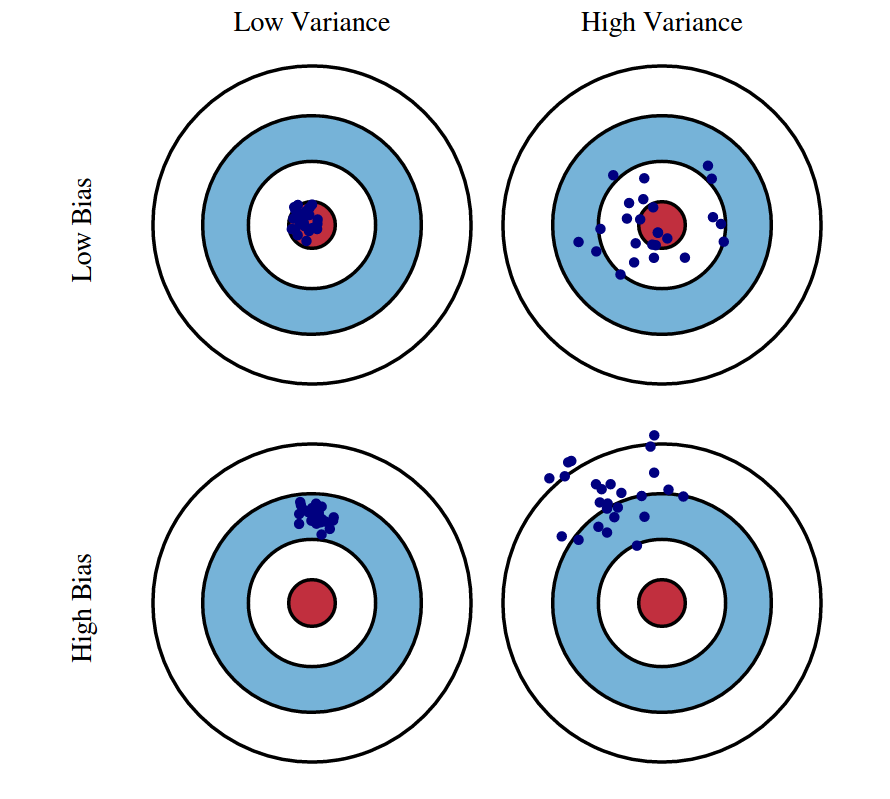
Figure 1 - Bias & Variance shown by data points on target
The illustration shows that an optimal model (top left) with low bias and low variance makes highly accurate predictions.
An overfit model (top right) with low bias and high variance reliably predicts data within the data’s mean values as a whole, but with a large difference between predicted and actual output on an individual basis.
On the other hand, is underfit model (bottom left) has high bias, low variance. It creates reliable and repeatable individual predictions, but as a whole are far off the actual data’s mean values.
With a high variance, high bias model (bottom right) is just totally wrong. Begin anew.
Image source: https://scott.fortmann-roe.com/docs/BiasVariance.html
What do underfit and overfit mean, really?

Figure 2 - Representations of various ML models trained to the same data.
Image source: https://towardsdatascience.com/understanding-the-bias-variance-tradeoff-165e6942b229
In Figure 2 we see an overfit model (left) where the curve of the prediction line is excessively dependent on the precise dataset it is trained on. This proves a unreliable prediction method once data outside the training set is tested against this curve. The prediction made by the model will result in a high degree of variance between the prediction and the reality of the new data. This overfit model corresponds to Figure 1, top right.
Next we see an underfit model (center) which predicts linearly though the data obviously curves. The error of the underfit model stems from the specific model choice implemented (in this case, constant linear) . This biased model corresponds to Figure 1, bottom left.
Finally we find an optimal model (right) that recognizes the curve of the data and finds a generalized mean that minimizes the overall distance between the data and the prediction. This corresponds to Figure 1, top left. The optimal, low bias, low variance model successfully navigates the Bias-Variance Tradeoff, which is our goal.
The optimal model minimizes the Total Error

Figure 4 - Graphing Bias^2, Variance, and their sum (plus Noise), Total Error, as a function of model complexity in terms of error.
As we have seen above, an overfit model responds to the variation in the data with a complex curve that in the end fails to predict well for new data, whereas an underfit model’s simple curve does little to capture the data variation at all.
We want to find some medium point of model complexity that avoids these extremes. So, as Figure 4 shows, we find the optimal model complexity where we minimize the total error, being the lowest possible sum of Variance + Bias^2 + Noise.
Image source: https://scott.fortmann-roe.com/docs/BiasVariance.html
Recognizing if bias or variance is your issue

Figure 3 - The Tell. Are we in Regime #1 or Regime #2?
Image source: https://www.cs.cornell.edu/courses/cs4780/2018fa/lectures/lecturenote12.html
So if your artificial intelligence or machine learning model is returning some unacceptable level of error, how do you know if the model is underfit or overfit? Should you solve for bias or variance?
Figure 3 above visualizes and compares the error rates of a model’s output based on both training data and the test data in relation to some pre-defined acceptable level of test error. There are two locations of interest: Regime #1 which indicates an overfit, high variance model and Regime #2 which indicates an underfit, biased model.
We recognize Regime #1 as overfit because while the total error of the model in predicting the output of the training dataset is within bounds of our acceptable test error threshold, the error of the model when predicting the output of the test data is far outside the bounds of acceptable error. The wide discrepency in error rate between a passing training dataset and a failing test dataset indicates the model too closely follows the idiosyncrasies of the training dataset, is thus overfit, and therefore the test error is due to high variance with the model.
In contrast, Regime #2 indicates an underfit model. There is a much smaller difference between the predictions of the test and training set. The model produces consistent answers, but those answers, irrespective of the dataset, are consistently too full of error. This indicates your model prediction does not follow where the data leads, thus is underfit, and the error is due to the bias of your specific model implementation.
Reducing High Variance
So to recap, if you observe the following when training and testing your artificial intelligence or machine learning model…
Symptoms:
Training error is much lower than test error
Training error is lower than the acceptable error
Test error is above the acceptable error
…then the poor performance of your model is due to overfitting. In which case, you should consider…
Remedies:
Add more training data. Perhaps your training data is too small a sample to draw a generalized conclusion, in which case more data would help smoothen out your prediction curve.
Choose a less complex model. Complex models such as Decision Trees are prone to high variance.
Use a bagging algorithm. This will resample and aggregate the data in a way that can simplify your model complexity.
Reducing High Bias
On the other hand if you observe…
Symptom:
Training error is higher than the acceptable error
…then the poor performance is due to underfitting and you should consider…
Remedies:
Use more complex model (e.g. kernelize, use non-linear models)
Add features
Use a boosting algorithm like CatBoost
Summary
We have seen that bias and variance are sources of model error that are identified by the relationship between your model’s training and test error rates and are each reduced by differing methods. Our goal as data scientists, machine learning and artificial intelligence engineers is to minimize the causes of these error to optimize the fit of our prediction models and to do so requires understanding The Bias-Variance Tradeoff.
Sources
Lecture 12: Bias-Variance Tradeoff by Cornell University Professor Kilian Weinberger
The Model Thinker by Scott E. Page
Practical Statistics for Data Scientists by Bruce, Bruce & Gedeck
Understanding the Bias-Variance Tradeoff by Seema Singh